[New post] Everything We Know About the Nvidia Ada Lovelace and GeForce RTX 40-Series
Nivedita Bangari posted: " By the end of the year, Nvidia's Ada architecture and the rumoured GeForce RTX 40-series graphics cards should be available, most likely in September or October. That's two years after the Nvidia Ampere architecture and, given Moore's 'Law' slowdown (or,"
By the end of the year, Nvidia's Ada architecture and the rumoured GeForce RTX 40-series graphics cards should be available, most likely in September or October. That's two years after the Nvidia Ampere architecture and, given Moore's 'Law' slowdown (or, if you prefer, death), perfectly on track. We have a lot of information about what to expect thanks to the Nvidia hack earlier this year.
There are a lot of theories floating about right now, and Nvidia hasn't stated much about its ambitions for Ada, which is also known as Lovelace. What we do know is that Nvidia has described its data centre Hopper H100 GPU, and we expect consumer goods to follow in the not-too-distant future, much like the Volta V100 and Ampere A100.
Ada appears to be a monster in principle, given on the "leaked" information we've seen thus far. It will have much more SMs and associated cores than existing Ampere GPUs, which should result in a significant performance improvement. Even if Ada turns out to be less powerful than the leaks suggested, it's safe to assume that performance from the top GPU — maybe an RTX 4090, though Nvidia may change the name again — will be a significant improvement over the RTX 3090 Ti.
Nvidia
At launch, the RTX 3080 was around 30% quicker than the RTX 2080 Ti, and the RTX 3090 contributed another 15%, at least when the GPU was pushed to its maximum by operating at 4K ultra. This is also something to consider. Even at 1440p extreme, if you're using a less powerful processor than one of the absolute finest for gaming, such as the Core i9-12900K or Ryzen 7 5800X3D, you can find yourself CPU constrained. To get the most out of the fastest Ada GPUs, a major system update will almost certainly be required.
When compared to the present Ampere generation, the most visible difference with Ada GPUs will be the amount of SMs. The AD102 might have 71 percent more SMs than the GA102 at the top. Even if nothing else in the architecture changes, we expect a considerable gain in performance.
In the worst-case scenario, simply porting the Ampere architecture from Samsung Foundry's 8N process to TSMC's 4N (or 5N or whatever) process and not changing much else with the architecture, adding more cores and keeping similar clocks should provide more than enough of a generational performance boost. Nvidia may produce far more than the bare minimum, but even the entry-level AD107 chip would be a good 30% or more better than the current RTX 3050.
Nvidia will most likely use partially deactivated chips to boost yields
For example, the Hopper H100 has 144 potential SMs, however only 132 SMs are activated on the SXM5 model, while 114 SMs are enabled on the PCIe 5.0 card. Nvidia will most likely release a top-end AD102 solution (i.e. RTX 4090) with between 132 and 140 SMs, with lower-tier variants having fewer SMs. Of course, this leaves the door open for a future card (such as the RTX 4090 Ti) with a fully active AD102 after yields have improved.
The Hopper H100 chip contains a total of 144 SMs, of which 132 are currently enabled in the top tier offering. It would be astonishing if Ada and Hopper both have the same 144 SMs. The GA100 had a maximum of 120 SMs, therefore Nvidia has only boosted the SM count by 20% with the H100. According to the alleged leaks, the AD102 has 71 percent more SMs than the GA102.
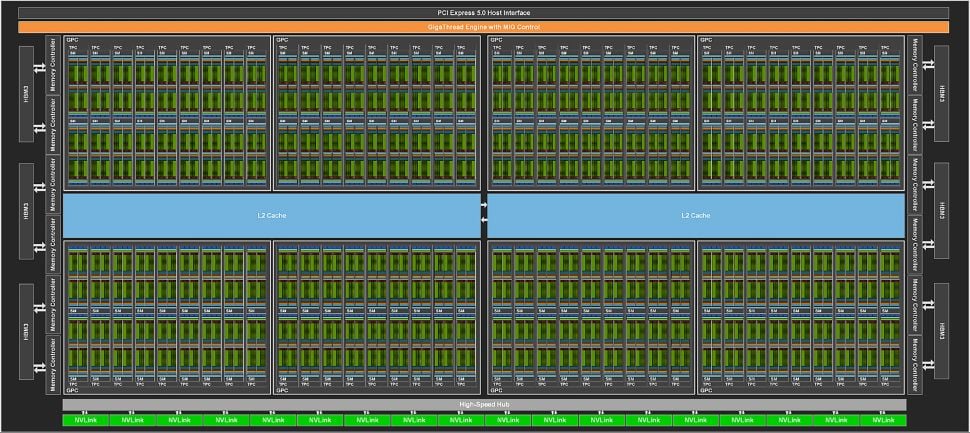
Hopper H100 has 144 SMs, spread out over 8 GPCs. Replace the HBM3 with GDDR6X, take out most of the FP64 cores and dumb down the tensor cores, then add in RT cores and you theoretically end up with Ada AD102. Maybe. (Image credit: Nvidia)
Professional GPUs, on the other hand, are one strong reason for AD102 to be a big chip. The A-series chips, such as the RTX A6000, show that Nvidia doesn't develop fully different silicon for the consumer and professional sectors. The GA102 chip is the same as in the RTX 3080 through 3090 Ti, with a few more functions enabled in the drivers. Ray tracing hasn't exactly exploded in popularity in the gaming world, but it's a huge thing in the professional sector, and adding even more RT cores would be a huge help to 3D rendering farms. Also, unlike the GA100 it replaces, the Hopper H100 does not feature any ray tracing technology.
The Ada GPUs will also be used for inference platforms that run AI and ML algorithms, which implies that more Tensor cores and computing will be available. The bottom line is that the alleged limit of 144 SMs isn't completely implausible, but it does require a fair dose of scepticism. Perhaps the Nvidia attack uncovered obsolete data, or individuals misinterpreted it.
The Ampere GA102 supports up to twelve 32-bit memory channels populated by GDDR6X, and we suspect AD102 will use a similar layout — just with faster memory speeds. (Image credit: Nvidia)
Micron has released roadmaps for GDDR6X memory with speeds of up to 24Gbps. Nvidia is presently the only business using GDDR6X for anything, and the latest RTX 3090 Ti only has 21Gbps memory. That begs the question of what will be using 24Gbps GDDR6X, and Nvidia Ada appears to be the only reasonable option. Lower-tier GPUs are also more likely to use ordinary GDDR6 rather than GDDR6X, which has a maximum speed of 18Gbps.
On lower-tier GPUs, there's a lot more space for bandwidth expansion if GDDR6X power consumption can be kept under control. Standard GDDR6 memory, clocked at 14–15 Gbps, is used in the current RTX 3050 through RTX 3070. We already know that 18Gbps GDDR6 will be available in time for Ada, so an RTX 4050 with 18Gbps GDDR6 should be able to keep up with the boost in GPU processing capability with ease. If Nvidia still requires extra bandwidth, it might use GDDR6X on lower-end GPUs.
credit: Source
On the Navi 21 GPU, AMD uses a huge L3 cache of up to 128MB, with 96MB on Navi 22, 32MB on Navi 23, and only 16MB on Navi 24. Surprisingly, the memory subsystem benefits from even the tiny 16MB cache. Overall, we didn't believe the Radeon RX 6500 XT was a spectacular card, but it can keep up with GPUs with nearly twice the memory bandwidth.
Each 32-bit memory controller looks to be paired with an 8MB L2 cache in the Ada design. That means that cards with a 128-bit memory interface will have 32MB of total L2 cache, whereas cards with a 384-bit memory interface will have 96MB. While this is less in some circumstances than AMD's Infinity Cache, we don't yet know about latencies or other features of the design. Because L2 cache has lower latencies than L3 cache, a slightly smaller L2 cache may easily keep up with a bigger but slower L3.
Take the 14 percent boost in bandwidth that comes with 24Gbps memory and combine it with a 50 percent gain in effective bandwidth, assuming Nvidia can get similar results with Ada. That would offer AD102 a 71 percent boost in effective bandwidth, which is near enough to the increase in GPU compute to ensure that everything works out smoothly.
Power consumption is one aspect of the Ada design that is sure to raise a few eyebrows toward Nvidia
Credit: source
Igor of Igor's Lab was the first to report on reports of Ada getting a 600W TBP (Typical Board Power). For many years, Nvidia graphics cards topped out at around 250W, so Ampere's jump to 350W on the RTX 3090 (and later RTX 3080 Ti) felt a little excessive. Then Nvidia disclosed the Hopper H100 specifications and debuted the RTX 3090 Ti, and 600W seemed less improbable.
Nvidia released the RTX 3080 and 3090 in September 2020, followed by the RTX 3070 a month later and the RTX 3060 Ti just over a month later. The RTX 3060 wasn't released until late February 2021, and Nvidia updated the series in June 2021 with the RTX 3080 Ti and RTX 3070 Ti. The RTX 3050 was not released until January 2022, and the RTX 3090 Ti wasn't released until the end of March 2022.
Each 32-bit memory controller looks to be paired with an 8MB L2 cache in the Ada design. That means that cards with a 128-bit memory interface will have 32MB of total L2 cache, whereas cards with a 384-bit memory interface will have 96MB. While this is less in some circumstances than AMD's Infinity Cache, we don't yet know about latencies or other features of the design. Because L2 cache has lower latencies than L3 cache, a slightly smaller L2 cache may easily keep up with a bigger but slower L3.









No comments:
Post a Comment